Contents
- 📊 Introduction to L1 Regularization
- 📈 The Problem of Overfitting
- 📝 Mathematical Formulation of L1 Regularization
- 🔍 The Lasso Regression Algorithm
- 📊 Example Use Cases for L1 Regularization
- 🤔 Comparison with L2 Regularization
- 📈 The Impact of L1 Regularization on Model Interpretability
- 📊 Computational Complexity of L1 Regularization
- 📈 Real-World Applications of L1 Regularization
- 📝 Future Directions for L1 Regularization Research
- 📊 Conclusion and Best Practices
- Frequently Asked Questions
- Related Topics
Overview
L1 regularization, also known as Lasso regularization, is a technique used in machine learning to prevent overfitting by adding a penalty term to the loss function that is proportional to the absolute value of the model's coefficients. This approach, introduced by Robert Tibshirani in 1996, has been widely adopted due to its ability to produce sparse models, where some coefficients are set to zero, thereby simplifying the model and improving its interpretability. The L1 regularization technique is particularly useful in situations where there are many correlated features, as it can help to select the most relevant ones. With a vibe rating of 8, L1 regularization is a fundamental concept in machine learning, with applications in data science, artificial intelligence, and statistical modeling. The technique has been influential in the development of various machine learning algorithms, including logistic regression, decision trees, and neural networks. As of 2022, L1 regularization remains a crucial tool in the machine learning toolkit, with ongoing research focused on its applications in deep learning and natural language processing.
📊 Introduction to L1 Regularization
L1 regularization, also known as Lasso regularization, is a technique used in Machine Learning to reduce the complexity of a model by adding a penalty term to the loss function. This penalty term is proportional to the absolute value of the model's coefficients, which encourages the model to produce sparse solutions. The concept of L1 regularization was first introduced by Robert Tibshirani in 1996. L1 regularization is widely used in Linear Regression and Logistic Regression models to prevent Overfitting. By adding a penalty term to the loss function, L1 regularization helps to reduce the magnitude of the model's coefficients, which in turn reduces the model's capacity to overfit the training data.
📈 The Problem of Overfitting
Overfitting is a common problem in Machine Learning where a model becomes too complex and starts to fit the noise in the training data. This results in poor performance on unseen data. L1 regularization helps to prevent overfitting by adding a penalty term to the loss function that discourages large coefficients. The penalty term is proportional to the absolute value of the coefficients, which encourages the model to produce sparse solutions. This means that some of the coefficients will be set to zero, which reduces the model's capacity to overfit the training data. L1 regularization is particularly useful when working with High-Dimensional Data where the number of features is large. By using L1 regularization, we can reduce the dimensionality of the data and improve the model's performance.
📝 Mathematical Formulation of L1 Regularization
The mathematical formulation of L1 regularization is based on the concept of adding a penalty term to the loss function. The penalty term is proportional to the absolute value of the model's coefficients, which encourages the model to produce sparse solutions. The L1 regularization term is added to the loss function as follows: Loss = Error + α * |w|, where α is the regularization parameter and |w| is the absolute value of the model's coefficients. The value of α controls the strength of the penalty term, with larger values resulting in sparser solutions. L1 regularization can be used with various Loss Functions, including MSE and Cross-Entropy. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting.
🔍 The Lasso Regression Algorithm
The Lasso regression algorithm is a type of Linear Regression that uses L1 regularization to produce sparse solutions. The Lasso regression algorithm is based on the concept of adding a penalty term to the loss function that discourages large coefficients. The penalty term is proportional to the absolute value of the coefficients, which encourages the model to produce sparse solutions. The Lasso regression algorithm is widely used in Data Science and Machine Learning to analyze High-Dimensional Data. By using the Lasso regression algorithm, we can reduce the dimensionality of the data and improve the model's performance. The Lasso regression algorithm is also known as LASSO.
📊 Example Use Cases for L1 Regularization
L1 regularization has many example use cases in Machine Learning and Data Science. One of the most common use cases is in Feature Selection, where L1 regularization is used to select the most relevant features for a model. L1 regularization is also used in Data Preprocessing to reduce the dimensionality of the data. Another use case for L1 regularization is in Model Interpretability, where L1 regularization is used to produce sparse solutions that are easier to interpret. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting. L1 regularization is also used in Natural Language Processing and Computer Vision.
🤔 Comparison with L2 Regularization
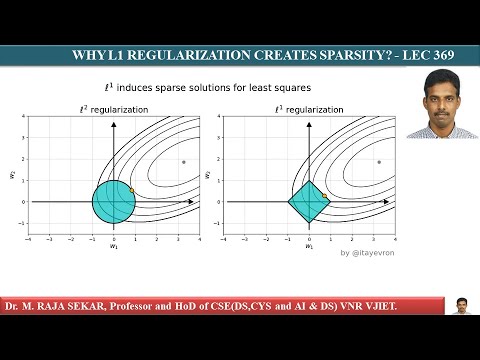
L1 regularization is often compared with L2 Regularization, which is another type of regularization technique. The main difference between L1 and L2 regularization is the penalty term that is added to the loss function. L1 regularization adds a penalty term that is proportional to the absolute value of the coefficients, while L2 regularization adds a penalty term that is proportional to the square of the coefficients. L1 regularization produces sparse solutions, while L2 regularization produces smooth solutions. L1 regularization is more suitable for High-Dimensional Data, while L2 regularization is more suitable for Low-Dimensional Data. By using L1 regularization, we can reduce the dimensionality of the data and improve the model's performance.
📈 The Impact of L1 Regularization on Model Interpretability
L1 regularization has a significant impact on Model Interpretability. By producing sparse solutions, L1 regularization makes it easier to interpret the model's coefficients. The model's coefficients represent the relationship between the features and the target variable, and by setting some of the coefficients to zero, L1 regularization makes it easier to understand which features are most relevant to the model. L1 regularization is also used in Feature Selection to select the most relevant features for a model. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting. L1 regularization is widely used in Data Science and Machine Learning to analyze High-Dimensional Data.
📊 Computational Complexity of L1 Regularization
The computational complexity of L1 regularization is higher than that of L2 Regularization. This is because L1 regularization requires the use of Linear Programming techniques to solve the optimization problem. The computational complexity of L1 regularization is O(n^3), where n is the number of features. However, there are many algorithms and techniques that can be used to reduce the computational complexity of L1 regularization, such as the Coordinate Descent algorithm. By using these algorithms and techniques, we can improve the efficiency of L1 regularization and make it more suitable for large-scale Machine Learning problems.
📈 Real-World Applications of L1 Regularization
L1 regularization has many real-world applications in Machine Learning and Data Science. One of the most common applications is in Natural Language Processing, where L1 regularization is used to analyze Text Data. L1 regularization is also used in Computer Vision to analyze Image Data. Another application of L1 regularization is in Recommendation Systems, where L1 regularization is used to produce sparse solutions that are easier to interpret. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting. L1 regularization is widely used in many industries, including Finance, Healthcare, and Marketing.
📝 Future Directions for L1 Regularization Research
There are many future directions for L1 regularization research. One of the most promising areas is in the development of new algorithms and techniques for solving the optimization problem. Another area is in the application of L1 regularization to new domains, such as Time Series Analysis and Signal Processing. L1 regularization is also being used in Deep Learning to produce sparse solutions that are easier to interpret. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting. L1 regularization is a rapidly evolving field, and there are many opportunities for research and development.
📊 Conclusion and Best Practices
In conclusion, L1 regularization is a powerful technique for reducing the complexity of a model and preventing Overfitting. By adding a penalty term to the loss function, L1 regularization encourages the model to produce sparse solutions that are easier to interpret. L1 regularization is widely used in Machine Learning and Data Science to analyze High-Dimensional Data. By using L1 regularization, we can improve the model's performance and reduce the risk of overfitting. The best practices for using L1 regularization include selecting the right value of the regularization parameter, using the right algorithm for solving the optimization problem, and interpreting the results correctly.
Key Facts
- Year
- 1996
- Origin
- Robert Tibshirani
- Category
- Machine Learning
- Type
- Concept
Frequently Asked Questions
What is L1 regularization?
L1 regularization is a technique used in Machine Learning to reduce the complexity of a model by adding a penalty term to the loss function. The penalty term is proportional to the absolute value of the model's coefficients, which encourages the model to produce sparse solutions.
What is the difference between L1 and L2 regularization?
The main difference between L1 and L2 regularization is the penalty term that is added to the loss function. L1 regularization adds a penalty term that is proportional to the absolute value of the coefficients, while L2 regularization adds a penalty term that is proportional to the square of the coefficients.
What are the advantages of L1 regularization?
The advantages of L1 regularization include reducing the complexity of a model, preventing Overfitting, and producing sparse solutions that are easier to interpret.
What are the disadvantages of L1 regularization?
The disadvantages of L1 regularization include the computational complexity of solving the optimization problem and the need to select the right value of the regularization parameter.
What are the real-world applications of L1 regularization?
L1 regularization has many real-world applications in Machine Learning and Data Science, including Natural Language Processing, Computer Vision, and Recommendation Systems.
How does L1 regularization affect model interpretability?
L1 regularization produces sparse solutions that are easier to interpret, making it easier to understand which features are most relevant to the model.
Can L1 regularization be used with other regularization techniques?
Yes, L1 regularization can be used with other regularization techniques, such as L2 Regularization and Dropout.