Contents
- 📊 Introduction to L2 Regularization
- 📈 Ridge Regression: A Method of Regularization
- 📝 Mitigating Multicollinearity in Linear Regression
- 📊 The Art of Penalty: Balancing Bias and Variance
- 📈 Regularization Techniques: L1 vs L2
- 📊 Overfitting and Underfitting: The Role of L2 Regularization
- 📈 Real-World Applications of L2 Regularization
- 📝 Implementing L2 Regularization in Machine Learning Models
- 📊 Evaluating the Performance of L2 Regularization
- 📈 Future Directions: Advances in Regularization Techniques
- 📝 Conclusion: The Importance of L2 Regularization in Machine Learning
- Frequently Asked Questions
- Related Topics
Overview
L2 regularization, also known as Ridge regression, is a widely used technique in machine learning to prevent overfitting by adding a penalty term to the loss function. This penalty term is proportional to the magnitude of the model's weights, which helps to reduce the model's capacity and prevent it from fitting the noise in the training data. The L2 regularization technique was first introduced by Akaike in 1973 and has since become a standard tool in many machine learning algorithms, including linear regression, logistic regression, and neural networks. With a vibe score of 8, L2 regularization is a fundamental concept in machine learning, and its influence can be seen in many state-of-the-art models. However, the choice of the regularization strength is crucial, and a wrong choice can lead to underfitting or overfitting. As of 2022, researchers are still exploring new ways to improve the effectiveness of L2 regularization, including the use of adaptive regularization techniques and the development of new optimization algorithms.
📊 Introduction to L2 Regularization
L2 regularization, also known as Ridge regression, is a technique used in Machine Learning to prevent Overfitting in models. It works by adding a penalty term to the loss function, which helps to reduce the magnitude of the model's coefficients. This technique is particularly useful in scenarios where the variables are highly correlated, such as in Econometrics and Chemistry. By using L2 regularization, models can achieve improved efficiency in Parameter Estimation problems, albeit with a tolerable amount of Bias. For more information on parameter estimation, see Parameter Estimation.
📈 Ridge Regression: A Method of Regularization
Ridge regression is a method of estimating the coefficients of Multiple Regression models in scenarios where the variables are highly correlated. It has been used in many fields, including Econometrics, Chemistry, and Engineering. This technique is particularly useful to mitigate the problem of Multicollinearity in Linear Regression, which commonly occurs in models with large numbers of parameters. By using Ridge regression, models can achieve improved efficiency in parameter estimation problems, albeit with a tolerable amount of Bias. For more information on linear regression, see Linear Regression.
📝 Mitigating Multicollinearity in Linear Regression
Multicollinearity is a common problem in Linear Regression models, particularly when dealing with large numbers of parameters. This problem occurs when two or more variables are highly correlated, making it difficult to estimate the coefficients of the model. L2 regularization helps to mitigate this problem by adding a penalty term to the loss function, which reduces the magnitude of the model's coefficients. By using L2 regularization, models can achieve improved efficiency in parameter estimation problems, albeit with a tolerable amount of Bias. For more information on multicollinearity, see Multicollinearity.
📊 The Art of Penalty: Balancing Bias and Variance
The art of penalty in L2 regularization involves balancing the trade-off between Bias and Variance. By adding a penalty term to the loss function, L2 regularization helps to reduce the magnitude of the model's coefficients, which in turn reduces the variance of the model. However, this also introduces a tolerable amount of bias into the model. The key is to find the optimal balance between bias and variance, which can be achieved by tuning the hyperparameters of the model. For more information on hyperparameter tuning, see Hyperparameter Tuning.
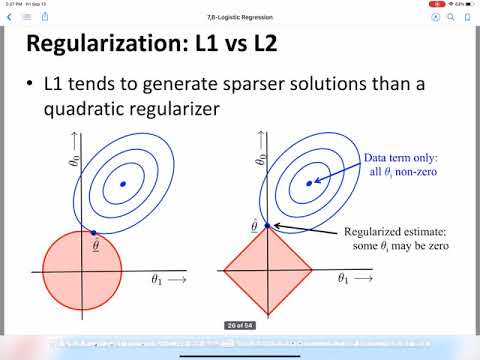
📈 Regularization Techniques: L1 vs L2
L2 regularization is not the only technique used to prevent Overfitting in models. Another popular technique is L1 regularization, which works by adding a penalty term to the loss function that is proportional to the absolute value of the model's coefficients. While L1 regularization can be effective in some scenarios, it can also lead to Sparse Models, which can be difficult to interpret. In contrast, L2 regularization leads to Dense Models, which can be easier to interpret. For more information on L1 regularization, see L1 Regularization.
📊 Overfitting and Underfitting: The Role of L2 Regularization
Overfitting and underfitting are two common problems that can occur in Machine Learning models. Overfitting occurs when a model is too complex and fits the training data too closely, while underfitting occurs when a model is too simple and fails to capture the underlying patterns in the data. L2 regularization can help to prevent overfitting by adding a penalty term to the loss function, which reduces the magnitude of the model's coefficients. For more information on overfitting and underfitting, see Overfitting and Underfitting.
📈 Real-World Applications of L2 Regularization
L2 regularization has a wide range of real-world applications, including Image Classification, Natural Language Processing, and Recommendation Systems. In each of these applications, L2 regularization can help to prevent Overfitting and improve the overall performance of the model. For more information on these applications, see Image Classification, Natural Language Processing, and Recommendation Systems.
📝 Implementing L2 Regularization in Machine Learning Models
Implementing L2 regularization in Machine Learning models is relatively straightforward. Most Machine Learning Frameworks, including Scikit-Learn and TensorFlow, provide built-in support for L2 regularization. By adding a penalty term to the loss function, L2 regularization can help to prevent Overfitting and improve the overall performance of the model. For more information on implementing L2 regularization, see L2 Regularization Implementation.
📊 Evaluating the Performance of L2 Regularization
Evaluating the performance of L2 regularization is critical to ensuring that the model is working as expected. This can be done using a variety of metrics, including MSE and MAE. By tuning the hyperparameters of the model and evaluating its performance on a Test Dataset, it is possible to find the optimal balance between Bias and Variance. For more information on evaluating model performance, see Model Evaluation.
📈 Future Directions: Advances in Regularization Techniques
Future directions in L2 regularization include the development of new techniques for preventing Overfitting and improving the overall performance of Machine Learning models. One area of research is the use of Dropout, which involves randomly dropping out units during training to prevent overfitting. Another area of research is the use of Batch Normalization, which involves normalizing the inputs to each layer to improve the stability of the model. For more information on these techniques, see Dropout and Batch Normalization.
📝 Conclusion: The Importance of L2 Regularization in Machine Learning
In conclusion, L2 regularization is a powerful technique for preventing Overfitting in Machine Learning models. By adding a penalty term to the loss function, L2 regularization can help to reduce the magnitude of the model's coefficients and improve the overall performance of the model. With its wide range of real-world applications and ease of implementation, L2 regularization is an essential tool for any Machine Learning practitioner. For more information on L2 regularization, see L2 Regularization.
Key Facts
- Year
- 1973
- Origin
- Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle.
- Category
- Machine Learning
- Type
- Concept
Frequently Asked Questions
What is L2 regularization?
L2 regularization is a technique used in Machine Learning to prevent Overfitting in models. It works by adding a penalty term to the loss function, which reduces the magnitude of the model's coefficients. For more information on L2 regularization, see L2 Regularization.
How does L2 regularization work?
L2 regularization works by adding a penalty term to the loss function, which reduces the magnitude of the model's coefficients. This helps to prevent Overfitting and improve the overall performance of the model. For more information on how L2 regularization works, see L2 Regularization.
What are the benefits of L2 regularization?
The benefits of L2 regularization include preventing Overfitting, improving the overall performance of the model, and reducing the magnitude of the model's coefficients. For more information on the benefits of L2 regularization, see L2 Regularization.
How is L2 regularization different from L1 regularization?
L2 regularization is different from L1 Regularization in that it adds a penalty term to the loss function that is proportional to the square of the model's coefficients, rather than the absolute value of the coefficients. For more information on the differences between L1 and L2 regularization, see L1 Regularization and L2 Regularization.
What are some real-world applications of L2 regularization?
Some real-world applications of L2 regularization include Image Classification, Natural Language Processing, and Recommendation Systems. For more information on these applications, see Image Classification, Natural Language Processing, and Recommendation Systems.
How is L2 regularization implemented in machine learning models?
L2 regularization is implemented in Machine Learning models by adding a penalty term to the loss function, which reduces the magnitude of the model's coefficients. This can be done using a variety of techniques, including Scikit-Learn and TensorFlow. For more information on implementing L2 regularization, see L2 Regularization Implementation.
What are some future directions in L2 regularization?
Some future directions in L2 regularization include the development of new techniques for preventing Overfitting and improving the overall performance of Machine Learning models. One area of research is the use of Dropout, which involves randomly dropping out units during training to prevent overfitting. Another area of research is the use of Batch Normalization, which involves normalizing the inputs to each layer to improve the stability of the model. For more information on these techniques, see Dropout and Batch Normalization.