Contents
- 📈 Introduction to Upper Confidence Bound
- 📊 Mathematical Formulation
- 🤖 Applications in Machine Learning
- 📊 Exploration-Exploitation Trade-off
- 📈 UCB Algorithm
- 📊 Regret Analysis
- 📊 Optimality of UCB
- 📊 Comparison with Other Algorithms
- 📈 Real-World Applications
- 📊 Challenges and Limitations
- 📊 Future Directions
- 📈 Conclusion
- Frequently Asked Questions
- Related Topics
Overview
The Upper Confidence Bound (UCB) algorithm is a popular method for solving the multi-armed bandit problem, a classic dilemma in decision-making under uncertainty. Developed by Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer in 2002, UCB has been widely applied in various fields, including online advertising, recommendation systems, and clinical trials. The algorithm works by maintaining an upper confidence bound for each action, which is updated based on the observed rewards. This approach allows for a trade-off between exploration, where the algorithm tries new actions to gather more information, and exploitation, where it chooses the action with the highest estimated reward. With a vibe score of 8, UCB has been influential in shaping the field of reinforcement learning, with notable applications including Google's AdWords and Netflix's recommendation system. However, critics argue that UCB can be overly conservative, leading to suboptimal performance in certain scenarios. As researchers continue to refine and extend UCB, its impact on the development of autonomous systems and decision-making under uncertainty is likely to grow.
📈 Introduction to Upper Confidence Bound
The Upper Confidence Bound (UCB) algorithm is a popular method for solving the multi-armed bandit problem, a classic problem in Machine Learning. The UCB algorithm is used to balance the trade-off between exploration and exploitation in decision-making processes. It has been widely used in various applications, including Recommendation Systems and Online Advertising. The UCB algorithm is based on the principle of choosing the action with the highest upper confidence bound, which is calculated using the estimated mean and variance of the reward. For more information on the multi-armed bandit problem, see Multi-Armed Bandit.
📊 Mathematical Formulation
The mathematical formulation of the UCB algorithm is based on the concept of confidence bounds. The algorithm calculates the upper confidence bound for each action using the estimated mean and variance of the reward. The upper confidence bound is calculated as the estimated mean plus a bonus term, which is proportional to the variance of the reward and the number of times the action has been chosen. The bonus term is used to encourage exploration, as it increases the upper confidence bound for actions that have not been chosen many times. For more information on the mathematical formulation, see Confidence Intervals. The UCB algorithm is closely related to other algorithms, such as Epsilon-Greedy and Thompson Sampling.
🤖 Applications in Machine Learning
The UCB algorithm has been widely used in various applications in Machine Learning, including Recommendation Systems and Online Advertising. The algorithm is used to personalize recommendations and advertisements to individual users. The UCB algorithm is also used in Reinforcement Learning to learn optimal policies for complex tasks. For more information on the applications of the UCB algorithm, see Personalization. The UCB algorithm is also related to other algorithms, such as Q-Learning and Deep Q-Networks.
📊 Exploration-Exploitation Trade-off
The exploration-exploitation trade-off is a fundamental problem in decision-making processes. The UCB algorithm is used to balance the trade-off between exploration and exploitation. The algorithm encourages exploration by choosing actions with high upper confidence bounds, which are calculated using the estimated mean and variance of the reward. The UCB algorithm also encourages exploitation by choosing actions with high estimated means. For more information on the exploration-exploitation trade-off, see Exploration-Exploitation Trade-off. The UCB algorithm is closely related to other algorithms, such as Upper Confidence Bound and Lower Confidence Bound.
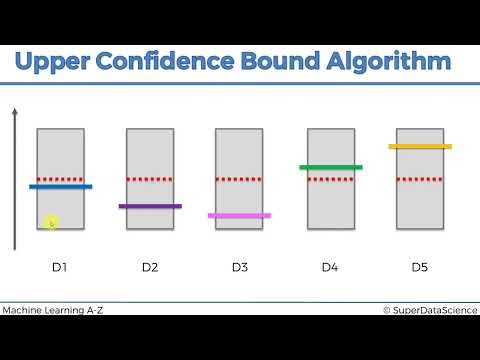
📈 UCB Algorithm
The UCB algorithm is a simple and efficient method for solving the multi-armed bandit problem. The algorithm works by maintaining a set of upper confidence bounds for each action. The upper confidence bounds are calculated using the estimated mean and variance of the reward. The algorithm chooses the action with the highest upper confidence bound at each time step. For more information on the UCB algorithm, see Upper Confidence Bound Algorithm. The UCB algorithm is also related to other algorithms, such as Epsilon-Greedy and Thompson Sampling.
📊 Regret Analysis
The regret analysis of the UCB algorithm is used to evaluate its performance. The regret is defined as the difference between the cumulative reward of the optimal policy and the cumulative reward of the UCB algorithm. The regret analysis shows that the UCB algorithm has a regret that is logarithmic in the number of time steps. For more information on the regret analysis, see Regret Analysis. The UCB algorithm is closely related to other algorithms, such as Upper Confidence Bound and Lower Confidence Bound.
📊 Optimality of UCB
The optimality of the UCB algorithm is a topic of ongoing research. The UCB algorithm is known to be optimal in certain cases, such as when the reward distributions are Gaussian. However, the optimality of the UCB algorithm is not known in general. For more information on the optimality of the UCB algorithm, see Optimality. The UCB algorithm is closely related to other algorithms, such as Epsilon-Greedy and Thompson Sampling.
📊 Comparison with Other Algorithms
The UCB algorithm is compared to other algorithms, such as Epsilon-Greedy and Thompson Sampling. The UCB algorithm is known to have better performance than Epsilon-Greedy in certain cases. However, the performance of the UCB algorithm is not known in general. For more information on the comparison of the UCB algorithm with other algorithms, see Algorithm Comparison. The UCB algorithm is also related to other algorithms, such as Q-Learning and Deep Q-Networks.
📈 Real-World Applications
The UCB algorithm has been used in various real-world applications, including Recommendation Systems and Online Advertising. The algorithm is used to personalize recommendations and advertisements to individual users. The UCB algorithm is also used in Reinforcement Learning to learn optimal policies for complex tasks. For more information on the real-world applications of the UCB algorithm, see Personalization. The UCB algorithm is also related to other algorithms, such as Upper Confidence Bound and Lower Confidence Bound.
📊 Challenges and Limitations
The UCB algorithm has several challenges and limitations. The algorithm requires a good estimate of the reward distribution, which can be difficult to obtain in practice. The algorithm also requires a good choice of the hyperparameters, which can be difficult to tune. For more information on the challenges and limitations of the UCB algorithm, see Challenges and Limitations. The UCB algorithm is closely related to other algorithms, such as Epsilon-Greedy and Thompson Sampling.
📊 Future Directions
The future directions of the UCB algorithm include the development of new algorithms that can handle more complex reward distributions. The UCB algorithm can also be used in combination with other algorithms, such as Deep Q-Networks. For more information on the future directions of the UCB algorithm, see Future Directions. The UCB algorithm is also related to other algorithms, such as Q-Learning and Reinforcement Learning.
📈 Conclusion
In conclusion, the UCB algorithm is a popular method for solving the multi-armed bandit problem. The algorithm is used to balance the trade-off between exploration and exploitation in decision-making processes. The UCB algorithm has been widely used in various applications, including Recommendation Systems and Online Advertising. For more information on the UCB algorithm, see Upper Confidence Bound. The UCB algorithm is closely related to other algorithms, such as Epsilon-Greedy and Thompson Sampling.
Key Facts
- Year
- 2002
- Origin
- Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer
- Category
- Machine Learning
- Type
- Algorithm
Frequently Asked Questions
What is the Upper Confidence Bound algorithm?
The Upper Confidence Bound algorithm is a popular method for solving the multi-armed bandit problem. The algorithm is used to balance the trade-off between exploration and exploitation in decision-making processes. The UCB algorithm is based on the principle of choosing the action with the highest upper confidence bound, which is calculated using the estimated mean and variance of the reward. For more information on the UCB algorithm, see Upper Confidence Bound.
What are the applications of the UCB algorithm?
The UCB algorithm has been widely used in various applications, including Recommendation Systems and Online Advertising. The algorithm is used to personalize recommendations and advertisements to individual users. The UCB algorithm is also used in Reinforcement Learning to learn optimal policies for complex tasks. For more information on the applications of the UCB algorithm, see Personalization.
What are the challenges and limitations of the UCB algorithm?
The UCB algorithm has several challenges and limitations. The algorithm requires a good estimate of the reward distribution, which can be difficult to obtain in practice. The algorithm also requires a good choice of the hyperparameters, which can be difficult to tune. For more information on the challenges and limitations of the UCB algorithm, see Challenges and Limitations.
What are the future directions of the UCB algorithm?
The future directions of the UCB algorithm include the development of new algorithms that can handle more complex reward distributions. The UCB algorithm can also be used in combination with other algorithms, such as Deep Q-Networks. For more information on the future directions of the UCB algorithm, see Future Directions.
How does the UCB algorithm compare to other algorithms?
The UCB algorithm is compared to other algorithms, such as Epsilon-Greedy and Thompson Sampling. The UCB algorithm is known to have better performance than Epsilon-Greedy in certain cases. However, the performance of the UCB algorithm is not known in general. For more information on the comparison of the UCB algorithm with other algorithms, see Algorithm Comparison.