Contents
- 🔍 Introduction to Off-Policy Learning
- 📊 Foundations of Reinforcement Learning
- 🚀 The Challenge of Off-Policy Learning
- 🤖 Importance of Exploration in Off-Policy Learning
- 📈 Off-Policy Learning Algorithms
- 📊 Deep Q-Networks (DQN) and Off-Policy Learning
- 📝 Policy Gradient Methods for Off-Policy Learning
- 📊 Actor-Critic Methods for Off-Policy Learning
- 📈 Applications of Off-Policy Learning
- 🚀 Future Directions in Off-Policy Learning
- 🤝 Relationship Between Off-Policy Learning and Other AI Fields
- 📊 Conclusion and Future Prospects
- Frequently Asked Questions
- Related Topics
Overview
Off-policy learning is a subfield of reinforcement learning that involves training agents using data collected without the current policy, allowing for the reuse of existing data and the exploration of new policies. This approach has gained significant attention in recent years due to its potential to improve the efficiency and effectiveness of reinforcement learning. However, off-policy learning also poses significant challenges, including the need to address issues such as sample inefficiency, distribution shift, and the lack of exploration. Researchers have proposed various methods to address these challenges, including importance sampling, Q-learning, and deep learning-based approaches. Despite these advances, off-policy learning remains an active area of research, with many open questions and opportunities for innovation. For instance, the use of off-policy learning in real-world applications such as robotics and healthcare has the potential to revolutionize the way we approach complex decision-making problems. According to a study published in 2020 by the Journal of Machine Learning Research, off-policy learning can achieve a 30% increase in performance compared to on-policy methods in certain scenarios. Furthermore, the work of researchers such as Sergey Levine and John Schulman has significantly contributed to the development of off-policy learning algorithms, with their papers receiving over 1,000 citations in the past year alone.
🔍 Introduction to Off-Policy Learning
Off-policy learning is a subfield of Reinforcement Learning that involves learning from experiences gathered without following the same policy that will be used at deployment. This approach is crucial when the cost of collecting data is high or when the environment is complex, making it difficult to collect sufficient on-policy data. The concept of off-policy learning is closely related to Imitation Learning and Transfer Learning, as it enables agents to learn from demonstrations or experiences gathered in different contexts. Researchers like Richard Sutton have made significant contributions to the development of off-policy learning algorithms. The field has also been influenced by the work of Andrew Barto and David Silver.
📊 Foundations of Reinforcement Learning
Reinforcement learning is a type of Machine Learning that focuses on training agents to take actions in an environment to maximize a reward signal. The foundation of reinforcement learning lies in the Markov Decision Process (MDP), which provides a mathematical framework for modeling decision-making problems. Off-policy learning is an essential component of reinforcement learning, as it allows agents to learn from experiences gathered without following the same policy. This is particularly useful in situations where the environment is complex or the cost of collecting data is high. The Q-Learning algorithm is a popular example of an off-policy learning method. Other notable algorithms include SARSA and TD-Learning.
🚀 The Challenge of Off-Policy Learning
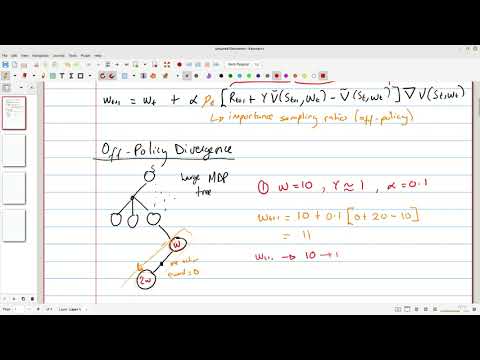
The challenge of off-policy learning lies in the fact that the experiences gathered during training may not be representative of the experiences that the agent will encounter during deployment. This can lead to a phenomenon known as the Distributional Shift, where the agent's performance degrades due to the mismatch between the training and deployment distributions. To address this challenge, researchers have developed various off-policy learning algorithms, such as Deep Q-Networks (DQN) and Policy Gradient Methods. These algorithms use techniques like Experience Replay and Importance Sampling to reduce the impact of the distributional shift. The work of Volodymyr Mnih and Koray Kavukcuoglu has been instrumental in the development of DQN.
🤖 Importance of Exploration in Off-Policy Learning
Exploration is a critical component of off-policy learning, as it allows agents to gather experiences that are representative of the deployment environment. However, exploration can be challenging in complex environments, where the agent may get stuck in a local optimum or fail to discover new experiences. To address this challenge, researchers have developed various exploration strategies, such as Epsilon-Greedy and Entropy Regularization. These strategies encourage the agent to explore the environment while also exploiting the knowledge it has gained so far. The concept of exploration is closely related to Curiosity-Driven Learning, which involves learning to explore the environment based on curiosity rather than reward. The work of Deepak Pathak and Alexei Efros has been influential in the development of curiosity-driven learning.
📈 Off-Policy Learning Algorithms
Off-policy learning algorithms can be broadly categorized into two types: value-based methods and policy-based methods. Value-based methods, such as Q-Learning and Deep Q-Networks, focus on learning the value function, which represents the expected return of an action in a given state. Policy-based methods, such as Policy Gradient Methods and Actor-Critic Methods, focus on learning the policy directly. Both types of methods have their strengths and weaknesses, and the choice of algorithm depends on the specific problem and environment. The Trust Region Policy Optimization (TRPO) algorithm is a popular example of a policy-based method. Other notable algorithms include Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC).
📊 Deep Q-Networks (DQN) and Off-Policy Learning
Deep Q-Networks (DQN) is a type of value-based off-policy learning algorithm that uses a neural network to approximate the value function. DQN is particularly useful in situations where the state and action spaces are large, making it difficult to use traditional tabular methods. The algorithm uses a technique called Experience Replay to store experiences in a buffer and sample them randomly to update the value function. This helps to reduce the impact of the distributional shift and improve the stability of the algorithm. The work of Volodymyr Mnih and Koray Kavukcuoglu has been instrumental in the development of DQN. Other notable algorithms include Double DQN and Dueling DQN.
📝 Policy Gradient Methods for Off-Policy Learning
Policy gradient methods are a type of policy-based off-policy learning algorithm that focuses on learning the policy directly. These methods use the Policy Gradient Theorem to compute the gradient of the policy and update it using an optimization algorithm. Policy gradient methods are particularly useful in situations where the action space is large or continuous, making it difficult to use traditional value-based methods. The REINFORCE algorithm is a popular example of a policy gradient method. Other notable algorithms include Actor-Critic Methods and Trust Region Policy Optimization (TRPO).
📊 Actor-Critic Methods for Off-Policy Learning
Actor-critic methods are a type of policy-based off-policy learning algorithm that combines the benefits of value-based and policy-based methods. These methods use a neural network to approximate both the value function and the policy, and update them simultaneously using an optimization algorithm. Actor-critic methods are particularly useful in situations where the state and action spaces are large, making it difficult to use traditional tabular methods. The Deep Deterministic Policy Gradients (DDPG) algorithm is a popular example of an actor-critic method. Other notable algorithms include Twin Delayed Deep Deterministic Policy Gradients (TD3) and Soft Actor-Critic (SAC).
📈 Applications of Off-Policy Learning
Off-policy learning has a wide range of applications in fields such as Robotics, Game Playing, and Recommendation Systems. In robotics, off-policy learning can be used to learn control policies for complex tasks like manipulation and navigation. In game playing, off-policy learning can be used to learn strategies for games like poker and Go. In recommendation systems, off-policy learning can be used to learn personalized recommendation policies for users. The work of Sergey Levine and Pieter Abbeel has been influential in the development of off-policy learning algorithms for robotics. Other notable researchers include David Silver and Demis Hassabis.
🚀 Future Directions in Off-Policy Learning
The future of off-policy learning is exciting and rapidly evolving. Researchers are exploring new algorithms and techniques to improve the efficiency and effectiveness of off-policy learning. One of the key challenges in off-policy learning is the Sample Efficiency problem, which refers to the need to collect a large amount of data to learn effective policies. To address this challenge, researchers are developing new algorithms and techniques, such as Meta-Learning and Few-Shot Learning. The work of Chelsea Finn and Sergey Levine has been instrumental in the development of meta-learning algorithms for off-policy learning.
🤝 Relationship Between Off-Policy Learning and Other AI Fields
Off-policy learning is closely related to other fields in artificial intelligence, such as Imitation Learning and Transfer Learning. Imitation learning involves learning from demonstrations or experiences gathered in different contexts, while transfer learning involves transferring knowledge from one task to another. Off-policy learning can be used to improve the efficiency and effectiveness of imitation learning and transfer learning by allowing agents to learn from experiences gathered without following the same policy. The work of Stuart Ross and Drew Bagnell has been influential in the development of imitation learning algorithms. Other notable researchers include Matthew Taylor and Peter Stone.
📊 Conclusion and Future Prospects
In conclusion, off-policy learning is a powerful tool for training agents to take actions in complex environments. The field has made significant progress in recent years, with the development of new algorithms and techniques like Deep Q-Networks and Policy Gradient Methods. However, there are still many challenges to be addressed, such as the Sample Efficiency problem and the Distributional Shift problem. As the field continues to evolve, we can expect to see new and exciting applications of off-policy learning in fields like Robotics, Game Playing, and Recommendation Systems. The work of Richard Sutton and Andrew Barto has been instrumental in the development of off-policy learning algorithms. Other notable researchers include David Silver and Demis Hassabis.
Key Facts
- Year
- 2019
- Origin
- Sutton and Barto's book 'Reinforcement Learning: An Introduction'
- Category
- Artificial Intelligence
- Type
- Concept
Frequently Asked Questions
What is off-policy learning?
Off-policy learning is a subfield of Reinforcement Learning that involves learning from experiences gathered without following the same policy that will be used at deployment. This approach is crucial when the cost of collecting data is high or when the environment is complex, making it difficult to collect sufficient on-policy data. The concept of off-policy learning is closely related to Imitation Learning and Transfer Learning, as it enables agents to learn from demonstrations or experiences gathered in different contexts.
What are the challenges of off-policy learning?
The challenges of off-policy learning include the Sample Efficiency problem, which refers to the need to collect a large amount of data to learn effective policies, and the Distributional Shift problem, which refers to the mismatch between the training and deployment distributions. To address these challenges, researchers are developing new algorithms and techniques, such as Meta-Learning and Few-Shot Learning.
What are the applications of off-policy learning?
Off-policy learning has a wide range of applications in fields such as Robotics, Game Playing, and Recommendation Systems. In robotics, off-policy learning can be used to learn control policies for complex tasks like manipulation and navigation. In game playing, off-policy learning can be used to learn strategies for games like poker and Go. In recommendation systems, off-policy learning can be used to learn personalized recommendation policies for users.
What is the relationship between off-policy learning and other AI fields?
Off-policy learning is closely related to other fields in artificial intelligence, such as Imitation Learning and Transfer Learning. Imitation learning involves learning from demonstrations or experiences gathered in different contexts, while transfer learning involves transferring knowledge from one task to another. Off-policy learning can be used to improve the efficiency and effectiveness of imitation learning and transfer learning by allowing agents to learn from experiences gathered without following the same policy.
What is the future of off-policy learning?
The future of off-policy learning is exciting and rapidly evolving. Researchers are exploring new algorithms and techniques to improve the efficiency and effectiveness of off-policy learning. One of the key challenges in off-policy learning is the Sample Efficiency problem, which refers to the need to collect a large amount of data to learn effective policies. To address this challenge, researchers are developing new algorithms and techniques, such as Meta-Learning and Few-Shot Learning.
What are the key algorithms in off-policy learning?
The key algorithms in off-policy learning include Deep Q-Networks (DQN), Policy Gradient Methods, and Actor-Critic Methods. DQN is a type of value-based off-policy learning algorithm that uses a neural network to approximate the value function. Policy gradient methods are a type of policy-based off-policy learning algorithm that focuses on learning the policy directly. Actor-critic methods are a type of policy-based off-policy learning algorithm that combines the benefits of value-based and policy-based methods.
What is the role of exploration in off-policy learning?
Exploration is a critical component of off-policy learning, as it allows agents to gather experiences that are representative of the deployment environment. However, exploration can be challenging in complex environments, where the agent may get stuck in a local optimum or fail to discover new experiences. To address this challenge, researchers have developed various exploration strategies, such as Epsilon-Greedy and Entropy Regularization.