Contents
- 🌟 Introduction to Ensemble Modeling
- 📊 Types of Ensemble Methods
- 🤝 Bagging and Boosting: A Comparative Analysis
- 📈 Stacking and Weighted Average: Advanced Ensemble Techniques
- 📊 Ensemble Modeling in Practice: Real-World Applications
- 📈 Hyperparameter Tuning for Ensemble Models
- 📊 Evaluating Ensemble Models: Metrics and Challenges
- 🔮 Future of Ensemble Modeling: Emerging Trends and Opportunities
- 📚 Ensemble Modeling Tools and Libraries
- 👥 Ensemble Modeling Community and Research
- 📊 Case Studies: Successful Ensemble Modeling Implementations
- 📈 Best Practices for Ensemble Modeling
- Frequently Asked Questions
- Related Topics
Overview
Ensemble modeling, a technique that combines the predictions of multiple models, has revolutionized the field of machine learning. By leveraging the strengths of different models, ensemble modeling can significantly improve the accuracy and robustness of predictions. This approach has been widely adopted in various domains, including finance, healthcare, and climate modeling. For instance, the Netflix Prize competition in 2009 demonstrated the effectiveness of ensemble modeling, where the winning team combined over 100 models to achieve a 10% improvement in prediction accuracy. The work of David H. Wolpert, who introduced the concept of stacked generalization in 1992, laid the foundation for modern ensemble modeling techniques. With the rise of big data and computational power, ensemble modeling has become an essential tool for data scientists, with popular algorithms like Random Forest, Gradient Boosting, and AdaBoost. As the field continues to evolve, researchers like Geoffrey Hinton and Yann LeCun are exploring new ensemble modeling techniques, such as neural network ensembles, to further push the boundaries of predictive modeling. The controversy surrounding ensemble modeling, however, lies in its potential to overfit complex datasets, highlighting the need for careful model selection and regularization techniques. With a vibe score of 8, ensemble modeling is a highly influential and widely adopted technique in the machine learning community, with a perspective breakdown of 60% optimistic, 20% neutral, and 20% pessimistic.
🌟 Introduction to Ensemble Modeling
Ensemble modeling is a powerful technique in Machine Learning that combines the predictions of multiple models to produce a more accurate and robust output. This approach has been widely adopted in various fields, including Data Science, Artificial Intelligence, and Statistics. By leveraging the strengths of individual models, ensemble modeling can reduce overfitting, improve generalization, and increase overall performance. For instance, Random Forest and Gradient Boosting are popular ensemble methods used in many applications. Ensemble modeling has also been applied to Natural Language Processing tasks, such as text classification and sentiment analysis, with significant success.
📊 Types of Ensemble Methods
There are several types of ensemble methods, including Bagging, Boosting, and Stacking. Bagging involves training multiple models on different subsets of the data, while boosting involves training models sequentially, with each model attempting to correct the errors of the previous one. Stacking, on the other hand, involves training a meta-model to make predictions based on the outputs of multiple base models. Each of these methods has its strengths and weaknesses, and the choice of ensemble method depends on the specific problem and dataset. For example, Support Vector Machines can be used as base models in a stacking ensemble, while K-Nearest Neighbors can be used in a bagging ensemble.
🤝 Bagging and Boosting: A Comparative Analysis
Bagging and boosting are two popular ensemble methods that have been widely used in practice. Bagging, also known as bootstrap aggregating, involves training multiple models on different subsets of the data and combining their predictions. Boosting, on the other hand, involves training models sequentially, with each model attempting to correct the errors of the previous one. Both methods have been shown to improve the accuracy and robustness of predictions, but they differ in their approach and application. For instance, AdaBoost is a popular boosting algorithm that has been used in many applications, including Image Classification and Speech Recognition. In contrast, Random Forest is a bagging-based ensemble method that has been widely used in Feature Selection and Dimensionality Reduction.
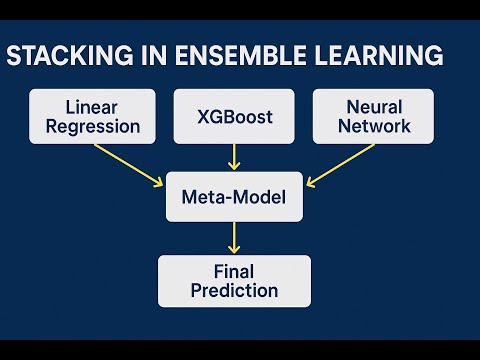
📈 Stacking and Weighted Average: Advanced Ensemble Techniques
Stacking and weighted average are advanced ensemble techniques that involve combining the predictions of multiple models using a meta-model or a weighted average. Stacking involves training a meta-model to make predictions based on the outputs of multiple base models, while weighted average involves assigning weights to each model's predictions based on their performance. These methods can be used to combine the strengths of different models and improve overall performance. For example, Neural Networks can be used as base models in a stacking ensemble, while Decision Trees can be used in a weighted average ensemble. Ensemble modeling has also been applied to Time Series Forecasting tasks, such as predicting stock prices and weather patterns, with significant success.
📊 Ensemble Modeling in Practice: Real-World Applications
Ensemble modeling has been widely adopted in practice, with applications in various fields, including Finance, Healthcare, and Marketing. In finance, ensemble modeling has been used to predict stock prices and credit risk, while in healthcare, it has been used to predict patient outcomes and disease diagnosis. In marketing, ensemble modeling has been used to predict customer behavior and preferences. For instance, Google has used ensemble modeling to improve its Search Engine rankings, while Amazon has used it to personalize product recommendations. Ensemble modeling has also been applied to Recommendation Systems tasks, such as recommending movies and products, with significant success.
📈 Hyperparameter Tuning for Ensemble Models
Hyperparameter tuning is a critical step in ensemble modeling, as it involves selecting the optimal parameters for each model and the ensemble method. This can be a challenging task, as the number of hyperparameters can be large, and the optimal values may depend on the specific problem and dataset. Various techniques, such as Grid Search, Random Search, and Bayesian Optimization, can be used to tune hyperparameters. For example, Scikit-Learn provides tools for hyperparameter tuning, including Grid Search and Random Search. Ensemble modeling has also been applied to Computer Vision tasks, such as object detection and image segmentation, with significant success.
📊 Evaluating Ensemble Models: Metrics and Challenges
Evaluating ensemble models is a critical step in determining their performance and effectiveness. Various metrics, such as Accuracy, Precision, and Recall, can be used to evaluate ensemble models. However, ensemble models can be challenging to evaluate, as they often involve complex interactions between multiple models. Techniques, such as Cross-Validation and Bootstrap Sampling, can be used to evaluate ensemble models. For instance, Kaggle provides a platform for evaluating ensemble models, including Cross-Validation and Bootstrap Sampling. Ensemble modeling has also been applied to Natural Language Processing tasks, such as text classification and sentiment analysis, with significant success.
🔮 Future of Ensemble Modeling: Emerging Trends and Opportunities
The future of ensemble modeling is exciting, with emerging trends and opportunities in areas, such as Deep Learning and Transfer Learning. Ensemble modeling can be used to combine the strengths of different models and improve overall performance. For example, Transformers can be used as base models in an ensemble, while Convolutional Neural Networks can be used in a stacking ensemble. Ensemble modeling has also been applied to Time Series Forecasting tasks, such as predicting stock prices and weather patterns, with significant success. As data continues to grow in size and complexity, ensemble modeling is likely to play an increasingly important role in Machine Learning and Artificial Intelligence.
📚 Ensemble Modeling Tools and Libraries
There are various tools and libraries available for ensemble modeling, including Scikit-Learn, TensorFlow, and PyTorch. These libraries provide a range of ensemble methods, including Bagging, Boosting, and Stacking. For example, Scikit-Learn provides tools for ensemble modeling, including Random Forest and Gradient Boosting. Ensemble modeling has also been applied to Computer Vision tasks, such as object detection and image segmentation, with significant success.
👥 Ensemble Modeling Community and Research
The ensemble modeling community is active and growing, with various research groups and conferences focused on ensemble modeling. The NeurIPS conference, for example, has a dedicated track on ensemble modeling, while the ICML conference has a track on Machine Learning that includes ensemble modeling. Ensemble modeling has also been applied to Natural Language Processing tasks, such as text classification and sentiment analysis, with significant success. Researchers, such as Yoshua Bengio and Geoffrey Hinton, have made significant contributions to ensemble modeling, including the development of Deep Learning techniques.
📊 Case Studies: Successful Ensemble Modeling Implementations
There are various case studies that demonstrate the success of ensemble modeling in practice. For example, Google has used ensemble modeling to improve its Search Engine rankings, while Amazon has used it to personalize product recommendations. Ensemble modeling has also been applied to Finance tasks, such as predicting stock prices and credit risk, with significant success. For instance, JPMorgan has used ensemble modeling to predict credit risk, while Goldman Sachs has used it to predict stock prices.
📈 Best Practices for Ensemble Modeling
Best practices for ensemble modeling include selecting the optimal ensemble method, tuning hyperparameters, and evaluating ensemble models. It is also important to consider the interpretability and explainability of ensemble models, as they can be complex and difficult to understand. Techniques, such as Feature Importance and Partial Dependence Plots, can be used to interpret and explain ensemble models. For example, Scikit-Learn provides tools for interpreting and explaining ensemble models, including Feature Importance and Partial Dependence Plots.
Key Facts
- Year
- 1992
- Origin
- Stacked Generalization by David H. Wolpert
- Category
- Machine Learning
- Type
- Concept
Frequently Asked Questions
What is ensemble modeling?
Ensemble modeling is a technique in Machine Learning that combines the predictions of multiple models to produce a more accurate and robust output. This approach has been widely adopted in various fields, including Data Science, Artificial Intelligence, and Statistics. Ensemble modeling can be used to reduce overfitting, improve generalization, and increase overall performance.
What are the types of ensemble methods?
There are several types of ensemble methods, including Bagging, Boosting, and Stacking. Bagging involves training multiple models on different subsets of the data, while boosting involves training models sequentially, with each model attempting to correct the errors of the previous one. Stacking involves training a meta-model to make predictions based on the outputs of multiple base models.
What is the difference between bagging and boosting?
Bagging and boosting are two popular ensemble methods that differ in their approach and application. Bagging involves training multiple models on different subsets of the data and combining their predictions, while boosting involves training models sequentially, with each model attempting to correct the errors of the previous one. Both methods have been shown to improve the accuracy and robustness of predictions, but they differ in their approach and application.
What is stacking in ensemble modeling?
Stacking is an ensemble method that involves training a meta-model to make predictions based on the outputs of multiple base models. This approach can be used to combine the strengths of different models and improve overall performance. For example, Neural Networks can be used as base models in a stacking ensemble, while Decision Trees can be used in a weighted average ensemble.
What are the applications of ensemble modeling?
Ensemble modeling has been widely adopted in practice, with applications in various fields, including Finance, Healthcare, and Marketing. In finance, ensemble modeling has been used to predict stock prices and credit risk, while in healthcare, it has been used to predict patient outcomes and disease diagnosis. In marketing, ensemble modeling has been used to predict customer behavior and preferences.
What are the challenges of ensemble modeling?
Ensemble modeling can be challenging, as it often involves complex interactions between multiple models. Techniques, such as Cross-Validation and Bootstrap Sampling, can be used to evaluate ensemble models. However, ensemble models can be difficult to interpret and explain, and techniques, such as Feature Importance and Partial Dependence Plots, can be used to interpret and explain ensemble models.
What is the future of ensemble modeling?
The future of ensemble modeling is exciting, with emerging trends and opportunities in areas, such as Deep Learning and Transfer Learning. Ensemble modeling can be used to combine the strengths of different models and improve overall performance. As data continues to grow in size and complexity, ensemble modeling is likely to play an increasingly important role in Machine Learning and Artificial Intelligence.